# La pseudonymisation par l'IA en pratique
Après avoir vu dans les grandes lignes les étapes d'un projet de pseudonymisation grâce à l'IA, nous revenons plus en détails dans cette partie sur ces différentes étapes pour présenter les choix, arbitrages et préconisations techniques que nous avons tirés de nos travaux pour la création d'un moteur de pseudonymisation pour les décisions du Conseil d'État. Ceux-ci sont disponibles sur GitHub.
# Formater ses données annotées
Afin de pouvoir utiliser les données annotées pour l'entraînement d'un algorithme d'apprentissage, celles-ci doivent être converties dans un format spécifique. Dans l'exemple ci-dessous, un document textuel (ici « Thomas CLAVIER aime beaucoup Paris. ») est alors structuré en un tableau, avec un mot par ligne, et deux colonnes, une pour le mot (ou token) et une pour l'annotation linguistique. Ce type de format s'appelle CoNLL.
| Token | Label |
|---|---|
| Thomas | B-PER |
| CLAVIER | I-PER |
| aime | O |
| beaucoup | O |
| Paris | B-LOC |
Plus particulièrement, nous utilisons le format IOB2, très commun pour les tâches d'apprentissage séquentiel comme la reconnaissance d'entités nommées, pour labéliser nos données. Ce format permet d'aider l'algorithme d'apprentissage à mieux repérer les entités. Le préfixe B- avant un label indique que le label est le début d'un groupe de mots, le préfixe I- indique que le label est à l'intérieur d'un groupe de mots, et le label O indique que le token n'a pas de label particulier. Il existe d'autres formats similaires à IOB2, tels que IOB/BIO, BILOU, et BIOES.
Le format CoNLL
CoNLL, pour « Conference on Natural Language Learning », est un format général, dont il existe de nombreuses versions, couramment employé pour les tâches de traitement du langage naturel, décrivant des données textuelles en colonne selon un nombre d'attributs (catégorie d'entité nommée, nature grammaticale, etc.). Le format IOB2 que nous utilisons est l'une des méthodes de labélisation du format CoNLL.
Il existe de très nombreux logiciels ou solutions d'annotation de données textuelles et les données annotées en sortie peuvent donc avoir différents formats (il existe en effet de multiples formats de données annotées). Pour transformer vos données annotées, un développement spécifique sera probablement nécessaire afin de les convertir au format IOB2, le format des données d'entrée de l'algorithme de reconnaissance d'entités nommées que nous avons choisi. Plusieurs exemples de fonctions et de librairies développées pour le Conseil d'État constitueront néanmoins un point de départ dans le répertoire GitHub de notre projet.
# Tokeniser le texte
Afin de mettre nos données sous format CoNLL, nous avons besoin d'abord d'identifier les mots individuels dans nos documents. Si l'on considère un document, composé de blocs de caractères, la tokenisation est la tâche qui consiste à découper ce document en éléments atomiques, en gardant ou supprimant la ponctuation. Par exemple :
| Phrase |
|---|
| Mes amis, mes enfants, l'avènement de la pseudonymisation automatique est proche. |
La phrase ci-dessus pourrait être tokenisée de cette manière :
| Token1 | Token2 | Token3 | Token4 | Token5 | Token6 | Token7 | Token8 | Token9 | Token10 | Token11 | Token12 | Token13 | Token14 | Token15 | Token16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mes | amis | , | mes | enfants | , | l | ' | avènement | de | la | pseudonymisation | automatique | est | proche | . |
Les tokens correspondent généralement aux mots, mais il est important de comprendre qu'une autre unité peut être choisie, par exemple les caractères. D'autres choix dans la façon de tokeniser peuvent avoir un impact sur les résultats de l'algorithme. Par exemple, le choix de conserver ou non la ponctuation a son importance. De manière pratique, il est important de bien comprendre la méthode de tokenisation utilisée par les algorithmes, afin de prendre en compte ces choix lors de l'étape finale d'occultation d'éléments identifiants dans le texte.
# Entraîner son modèle
Dans le code que nous avons développé, nous utilisons la librairie Open Source Flair. Celle-ci permet en effet d'utiliser de nombreux modèles de langage, par exemple les modèles Flair, Bert et CamemBERT et même de combiner plusieurs de ces modèles. Un modèle de langage permet pour chaque mot d'obtenir une représentation vectorielle (ou embedding). Ces embeddings sont ensuite passés à un classificateur BiLSTM-CRF qui attribue à chaque mot une des classes du jeu de données d'entraînement.
L'entraînement d'un tel classificateur nécessite de choisir la valeur d'un certain nombre d'hyper-paramètres. Les hyper-paramètres sont les paramètres de l'algorithmes qui sont fixés avant l'apprentissage, par opposition aux paramètres de l'algorithmes qui sont fixés de manière itérative au cours de l'apprentissage. Des exemples de configuration avec des explications des différents hyper-paramètres et de leur impact sont disponibles dans la section correspondante du répertoire GitHub.
Nous proposons un exemple de module permettant d'entraîner un algorithme de reconnaissance d'entités nommées via la librairie Flair à partir d'un corpus annoté. Enfin, pour aller plus loin, la librairie Flair propose un module très pratique permettant de fixer les valeurs optimales des hyper-paramètres optimaux pour l'apprentissage.
# Valider ses résultats
La validation des performances du modèle et la mise en production est un double processus reposant sur l'analyse de métriques et sur l'expérience humaine, comme nous l'avons vu dans la partie précédente. Comme illustré ci-dessous dans le cas de notre outil de pseudonymisation des décisions de justice, cette validation des résultats est charnière pour décider ou non du passage en production, c'est-à-dire du déploiement pour utilisation par les métiers.
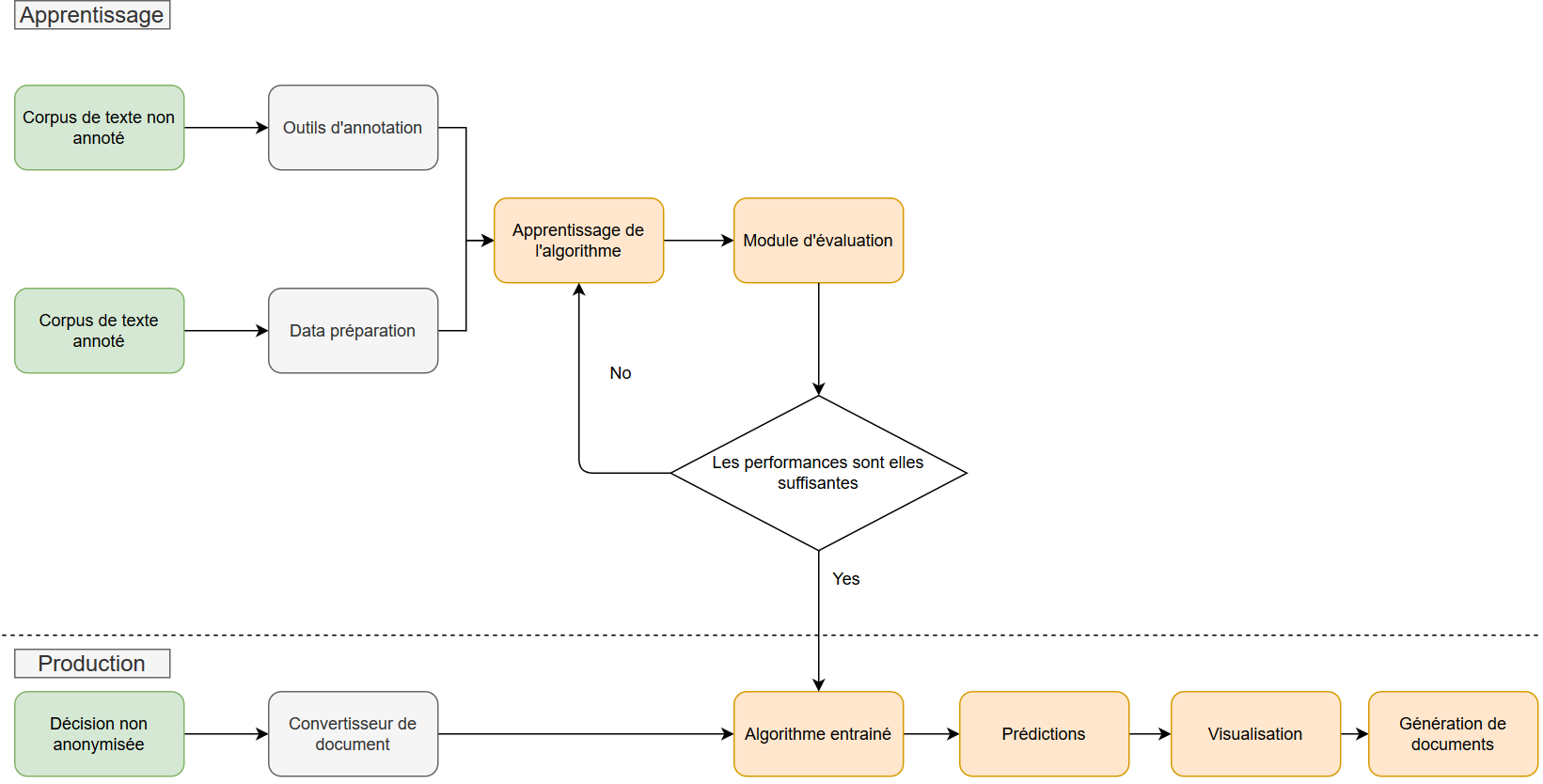
Pour permettre cette double analyse métriques/métiers, notre module de génération de documents pseudonymisés permet de produire en sortie des fichiers labélisés, au format CoNLL, et ainsi :
- d'utiliser des métriques permettant de comparer, pour un document ayant été annoté manuellement, la pseudonymisation par l'algorithme à celle réalisée manuellement. On utilise généralement le score F1 pour mesurer la performance du modèle ;
- de charger dans notre outil d'annotation basé sur Doccano un fichier mettant en avant les différences entre les annotations provenant de sources différentes, indiquant en rouge les labels en désaccord et en vert les labels en accord.
# Pseudonymiser de nouveaux documents
Le modèle entraîné permet d'attribuer une catégorie à chaque token du document à pseudonymiser. Les sorties de l'algorithme de reconnaissance d'entités nommées ne permettent donc pas d'obtenir directement le document peudonymisé, mais est nécessaire d'ajouter une brique pour remplacer les mots identifiés comme des données à caractère personnel par un alias. Pour le bon fonctionnement de cette étape, il est très important de fournir à l'algorithme un document tokenisé selon une méthode identique à celle utilisée pour entraîner l'algorithme.
# Quelles ressources disponibles pour pseudonymiser ?
# Les librairies
De nombreuses librairies open-source permettent d'entraîner et d'utiliser des algorithmes de reconnaissance d'entités nommées. Parmi celles-ci, Flair et SpaCy présentent l'avantage de proposer des algorithmes à l'état de l'art tout en facilitant l'expérience utilisateur.
- Flair est un framework simple pour le NLP. Il permet d'utiliser des modèles de NLP à l'état de l'art sur des textes de tout genre, en particulier des algorithmes de reconnaissance d'entité nommées et des embeddings pré-entraînés
- SpaCy est un module Python à forte capacité d'industrialisation pour le NLP rédigée en Python et Cython. Il implémente les toutes dernières recherches dans le domaine du traitement du langage naturel et a été conçu pour être utilisé en production. Il possède des modèles statistiques et des embeddings pré-entraînés.
- Stanza est une librairie Python de l'Université de Stanford qui utilise la très connue librairie CoreNLP comme moteur NLP. Ses composants permettent un entraînement et une évaluation efficace avec vos propres données annotées. La boîte à outils est conçue pour être parallèle entre plus de 70 langues, en utilisant le formalisme des dépendances universelles.
Si SpaCy est la librairie la plus rapide, Flair est celle que nous avons choisie pour le développement de notre outil de pseudonymisation, et ce pour la performance de son algorithme de reconnaissance d'entités.
# Outils d'annotation
Comme évoqué dans la partie précédente, il existe de nombreuses interfaces d'annotation, notamment en open source comme Doccano, WebAnno et Universal Data Tool. Ces outils fournissent des fonctionnalités d'annotation pour la classification de texte, la labélisation de mots et d'autres tâches classiques de traitement du langage naturel. Il est ainsi possible de créer rapidement des données d'entraînement pour l'analyse des sentiments, la reconnaissance d'entités nommées, la synthèse de texte, etc.
# Voir la pseudonymisation en action
Vous pouvez explorer notre démo pseudonymisation en ligne et retrouver le code de cet outil sur notre dépôt Git.